
Text transformation and analysis has never exactly been Excel’s strong suit. Sure, native text functions have significantly improved in recent years with new parsing and even regular expression functions, but in my opinion the real game-changer has been the integration of Python in Excel.
Plus, Python’s extensive history with text manipulation, and the sheer volume of tasks it’s been used for, means there’s far more training data available for Copilot to leverage. This, in my experience at least, translates to Copilot understanding text-related prompts even better than pure Excel tasks. With this combination of Python’s power and Copilot’s clarity, tasks that would have been complex, cumbersome, or outright impossible using Excel alone now become surprisingly straightforward….assuming you clearly know what you’re after and can express it effectively in your prompts.
Let’s dive into some of these use cases for quick wins in Python-powered text transformations right within Excel. You can download the exercise file below:
If you haven’t explored the Advanced Analysis features of Python in Excel yet, take a look at this post:
Fuzzy matching
We have a small set of customer reviews, and one useful step here would be to standardize them for spelling and consistency. This scenario comes up frequently: for example, with customer names, product titles, or vendor lists. Imagine you have a messy dataset of manually-entered customer names, filled with typos or variants like “General Electric,” “Gen Electric,” and “GE Corp.” You’d want to match these against a clean, authoritative dataset as your “source of truth.”
Fuzzy matching helps identify approximate matches and standardize or replace those messy entries, improving consistency, accuracy, and data integrity for your analysis.
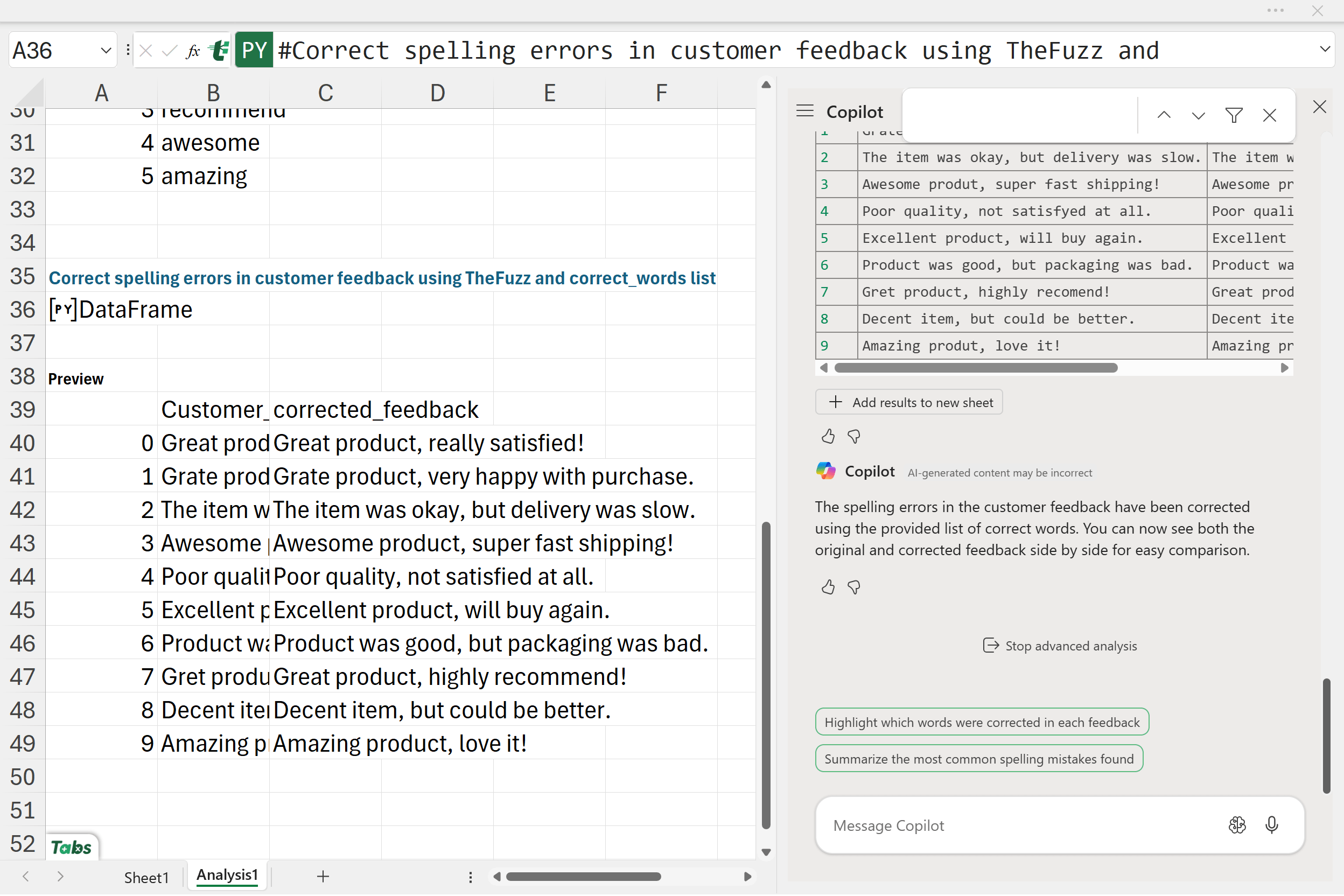
Luckily, Python in Excel includes a fuzzy matching package called TheFuzz. You might be familiar with fuzzy matching if you’ve used it in Power Query, but unfortunately, Power Query isn’t currently very Copilot-friendly. Python in Excel, however, integrates seamlessly with Copilot, making it a great alternative for this task:
Correct spelling errors in the customer_feedback column. Use the TheFuzz library to match words against a list of correct words in the correct_words table. Replace misspelled words with the closest match if the similarity score is above 80 using fuzz.ratio. Create a new column corrected_feedback with the corrected text.
At the moment, Advanced Analysis can’t directly reference tables other than the one you’re analyzing, so you’ll likely need to copy and paste the values from your correct_words table. From there, Copilot can help turn that pasted data into a working DataFrame and handle the corrections. Once done, you’ll have a corrected_feedback column that Copilot should intelligently use as the “source of truth” going forward.
Just keep in mind: fuzzy matching is probabilistic, so it might not always align perfectly with your judgment!
Sentiment analysis
Next, we’ll ask Copilot to perform sentiment analysis on the corrected_feedback column, classifying each comment as positive, negative, or neutral:
Perform sentiment analysis on the corrected_feedback column. Classify each comment as positive, negative, or neutral.
Sentiment analysis is valuable because it helps quickly identify customer perceptions and attitudes at scale, allowing businesses to pinpoint areas of success or concern.
While Excel previously offered sentiment analysis through a free add-in, one downside was a lack of transparency: it was difficult to audit or understand precisely how Excel arrived at each sentiment classification.
With Python in Excel, the exact Python code used is generated directly by Copilot, making the analysis transparent, reproducible, and easy to audit or adjust as needed.

Keyword extraction
Next, we’ll instruct Copilot to pull out important keywords from each comment in the corrected_feedback column, removing common, less meaningful words known as “stopwords” (such as “the,” “is,” “and,” etc.). The resulting keywords will then be placed in a new column called keywords, separated by commas.
Extract keywords from the corrected_feedback column by removing stopwords and output a new column keywords. Separate the keywords by comma.
Keyword extraction is valuable because it distills longer, free-form comments into concise, structured insights. This makes it easier to quickly identify common themes, emerging trends, and frequently mentioned topics, enabling businesses to rapidly understand customer sentiment, issues, or areas of praise without manually reading every review.

Word clouds and frequency visualizations
Next, we’ll instruct Copilot to generate a word cloud from all the feedback text, excluding stopwords. A word cloud visually highlights frequently mentioned words by displaying them in sizes proportional to their frequency. Larger words are mentioned more often.
Create a word cloud from all feedback text, excluding stopwords.

Word clouds can be appealing due to their visual impact and ease of interpretation, quickly revealing dominant themes. However, they’re not ideal for precise comparisons or clear numerical insights, as differences in word sizes can be ambiguous. This is why you might prefer a simpler visualization like a bar plot, as prompted here:
Create a bar plot of the most common words in the feedback text, excluding stopwords.

When examining the resulting bar plot, you might notice a typo… did you see “grate”? It seems this was intended to be “great,” but fuzzy matching missed it. This highlights the importance of verifying results after automated transformations.
Recap & conclusion
From here, you could consider experimenting further by refining the fuzzy matching threshold to catch more typos, applying additional text preprocessing like stemming or lemmatization for consistency, or exploring more advanced sentiment models tailored specifically to your data or business context.
In this post, you’ve seen how Python in Excel, paired with Copilot, makes advanced text transformations such as fuzzy matching, sentiment analysis, keyword extraction, and visualization accessible and transparent… tasks that used to be difficult, cumbersome, or opaque in Excel alone.
What questions do you have about text transformations with Python in Excel or Python in Excel more broadly? Leave them in the comments below.