
As an Excel trainer with a focus on data analytics, I have instructed thousands of spreadsheet users in Python. This extensive experience has allowed me to analyze patterns in the learning process.
Below are several frequent errors and misconceptions I’ve observed, especially among Excel users, who often approach problems with a distinct mindset and set of expectations.
Case sensitivity
A prevalent challenge for newcomers to Excel is understanding case sensitivity. Consider the ABS() function as a straightforward example. In Excel, case sensitivity is not an issue; users are free to use any case they prefer.
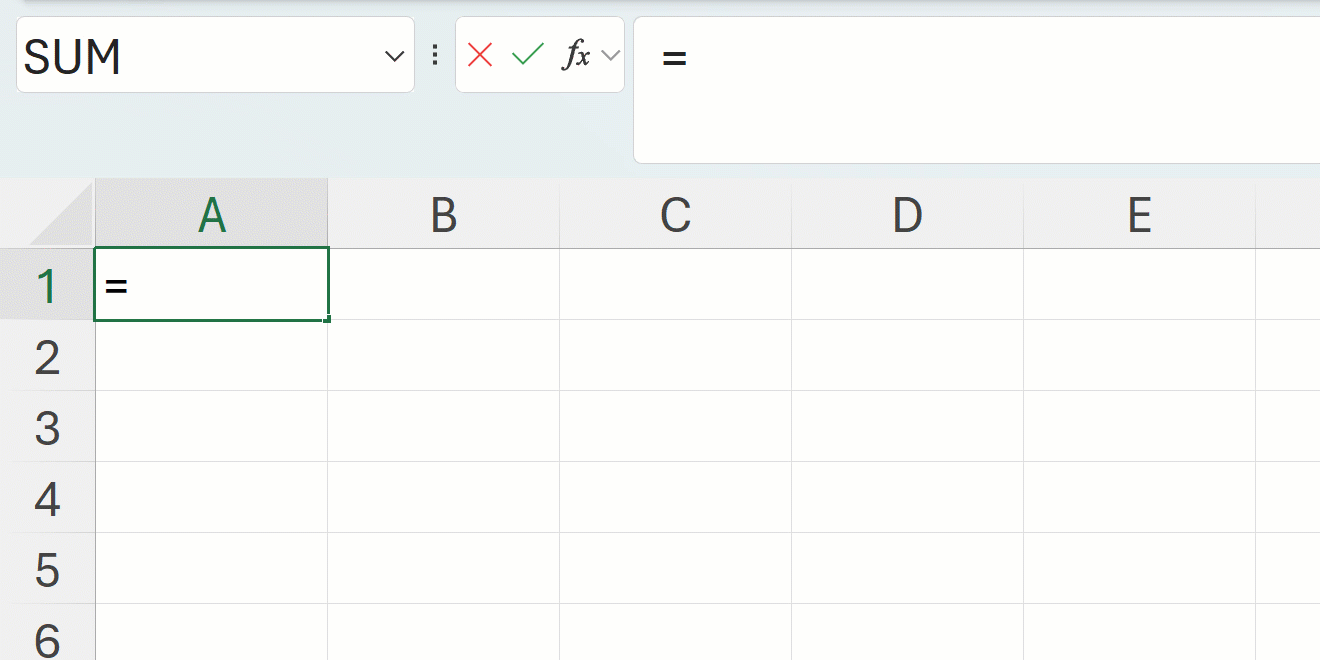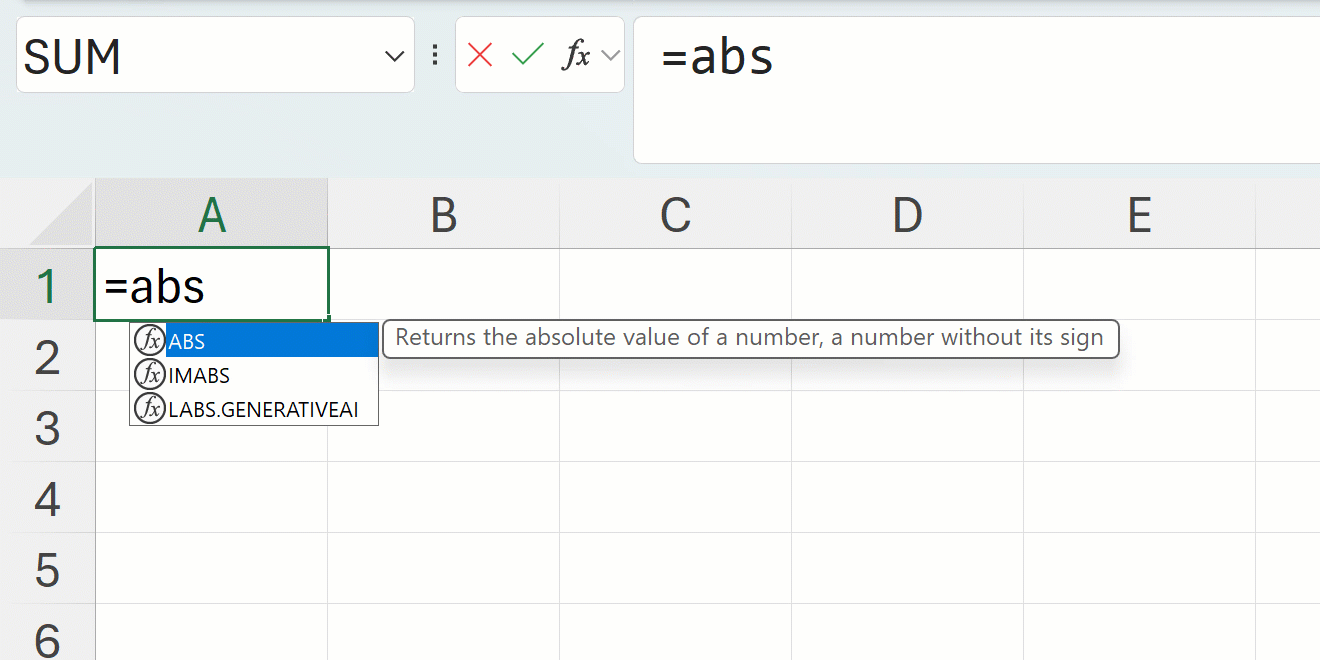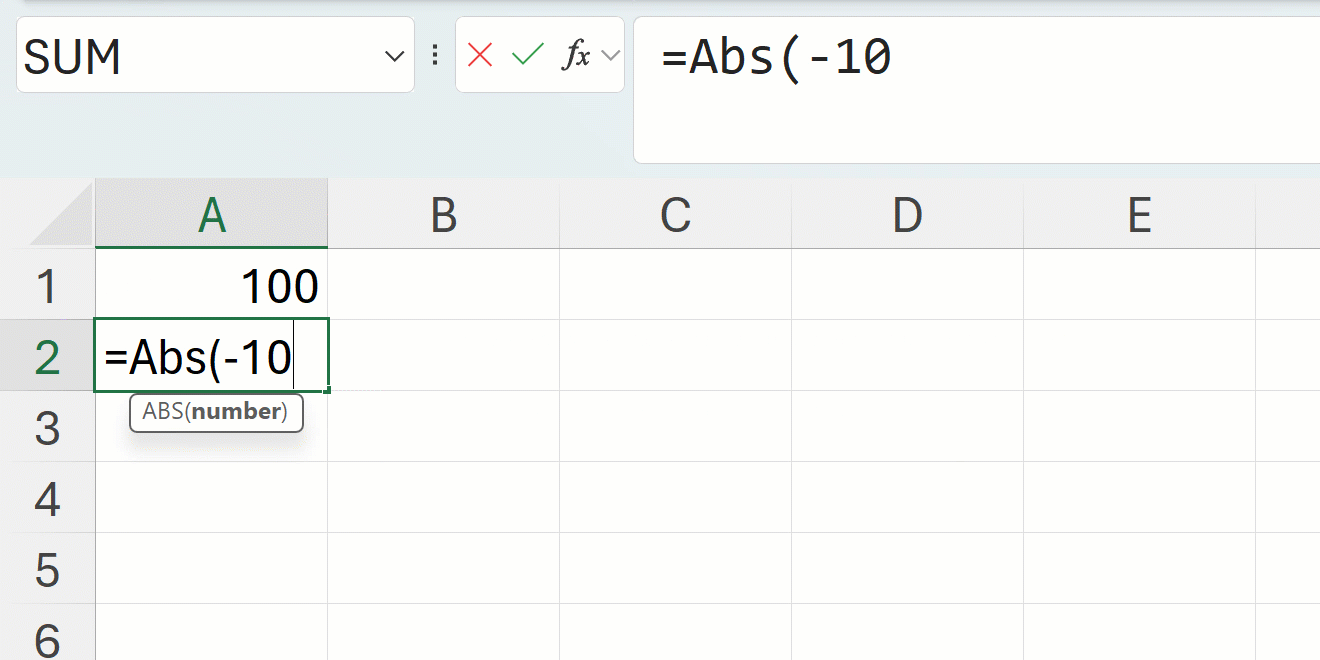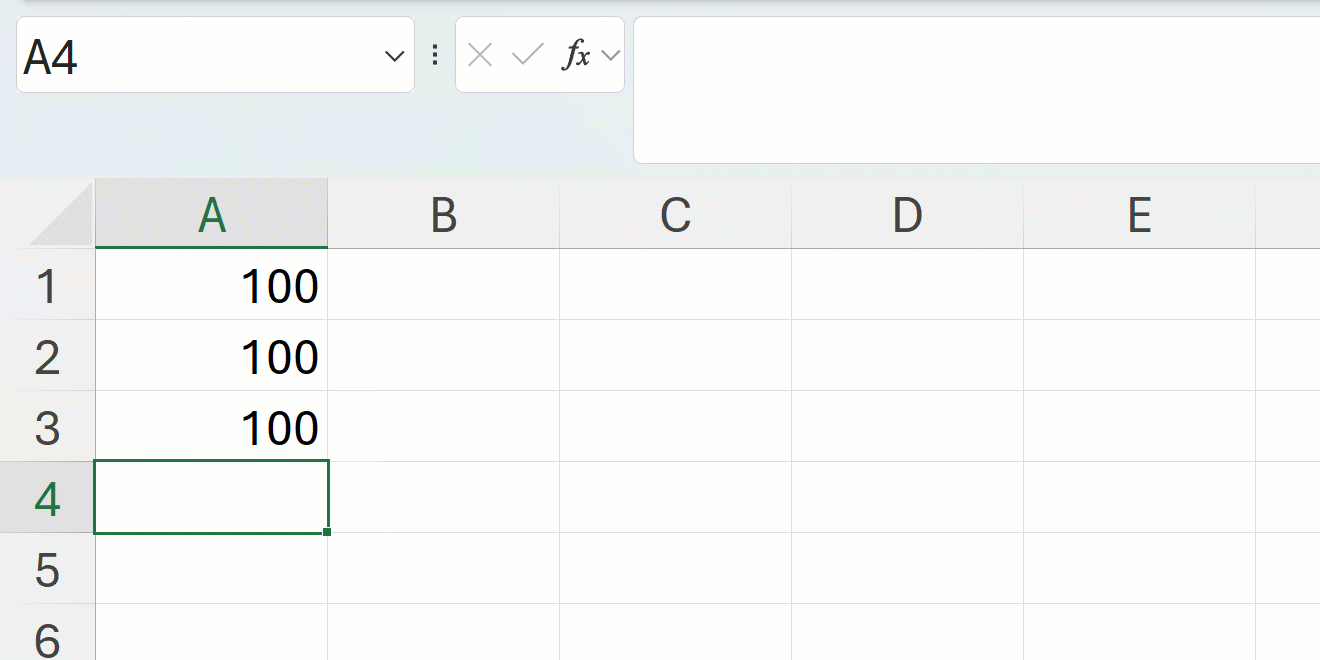
Python has a similar function, abs(), but this one is case sensitive; ABS() or Abs() will not work.
In Python, this principle applies to all elements: functions, packages, variable names, and more. Python demands precision in the way inputs are defined, and case sensitivity is a key aspect of this precision.
Storing versus printing objects
Excel users often encounter difficulty grasping the distinction between assigning data to an object and displaying the contents of that object. I find it useful to liken the assignment of an object in Python to placing it inside a box. However, placing an item in a box is not equivalent to viewing its contents, which is what the ‘print’ function accomplishes.
Unlike Python, Excel simplifies this process. When you use a function in Excel, the result is immediately visible without an additional step.
Although saving data in an object before printing it might appear burdensome and somewhat repetitive, it is this very concept of data assignment that endows Python with its strength. This approach contrasts sharply with Excel, where calculations are performed on-the-fly and results are generated immediately.
Indentation
Python, unlike Excel, is a programming language that requires proper indentation to execute code blocks correctly.
Indentation does not apply to Excel formulas, as they are not written in a language that relies on indentation to organize code. Excel formulas are typically confined to single-line expressions entered directly into cells to perform calculations or manipulate data. These formulas lack the code blocks or sequences that in programming require indentation for structural organization.
Excel users generally do not encounter issues with indentation while learning elementary concepts like lists and Pandas DataFrames. The challenge arises as they advance to more complex subjects such as functions and loops, where understanding and applying indentation becomes crucial for reconciling the differences between these two environments.
Zero-based indexing
Python’s counting method may initially perplex Excel users due to its use of zero-based indexing. In Python, the indices of items in a sequence start at zero, unlike Excel’s INDEX() function, which starts at one. This notebook illustrates the differences between Excel’s INDEX() function and Python’s indexing operations:
You can refer to the source post in its entirety here:
How packages work
Packages are essential to Python, especially for data analysis, and are a concept that new Excel users often find challenging. Specifically, they struggle with differentiating the workflow of installing packages from loading them.
To explain the availability, installation, and loading of packages, I find a smartphone analogy useful:
Like a smartphone equipped with essential utility apps such as a timer or calendar, Python includes a suite of base packages in its Standard Library. For more specialized tasks, however, you may need to install additional packages from a repository, similar to an “app store.”
Once a package is installed through a one-time download, it still requires loading every time you begin a new session before you can use it.
This process is markedly different from the typical Excel workflow. In Excel, all functions and features are readily available upon startup, except for add-ins, which can be installed and loaded visually as required.
How and where to store data
Another significant distinction between Python and Excel is their respective approaches to data access and storage.
Excel stores data directly within the workbook. When you enter data into Excel, it is embedded into the .xls or .xlsx file, making everything accessible within this single container. The workbook’s structure and its data are integrated, allowing you to move, share, or backup the entire file as a complete package of data and structure.
Conversely, Python scripts or programs, such as Jupyter notebooks, usually do not encapsulate data. Instead, they serve as tools to process, analyze, and manipulate data located externally. This data might be stored in a local file like a .csv, .txt, or .json, retrieved from a database, or sourced from an API or the web.
Python scripts act as a guide on how to interact with data, rather than serving as its repository. The data is kept in its original location, with the Python code reading from and writing to that place. This decoupling facilitates more flexible and automated data processing, as the same script can be adapted for various datasets by simply altering the data inputs.
In essence, Python offers a more decentralized experience. Scripts, programming commands, and files exist separately, contrasting with the integrated nature of Excel.
How directories work
Regarding the storage of data in files external to Python, there’s a requirement to import those files into Python for utilization. In Excel, importing data is straightforward: you simply use a point-and-click interface to find the desired workbook.
In Python environments, however, you often need to type out the file path to the file you want to use. Understanding directories is crucial in this context. It’s important to know your working directory, which is the folder where your notebook or script is active, as this location is referenced when accessing or saving files. You can manipulate the working directory and create new directories within Python using code or command-line instructions, which helps keep your files orderly and retrievable.
Excel users might initially find concepts like working directories, absolute, and relative file paths challenging. I recommend practicing with the path.isfile() function from Python’s os module to become proficient in verifying file existence across the file system. This is demonstrated in Chapter 11 of my book Advancing into Analytics where I discuss these concepts further.
What were your pitfalls?
These common challenges are what I’ve observed from my extensive experience teaching Python to Excel users. However, as the saying goes, “individual results may vary.” I’m curious to hear about the specific hurdles you encountered when transitioning from Excel to Python and the strategies you employed to overcome them.
Share your experiences in the comments below. I look forward to learning about your unique journey and exchanging tips and tricks that could benefit others.